Frontier data for frontier AI
We develop benchmarks, evaluation environments, and large-scale human datasets to fuel AI breakthroughs at the frontier, all through our marketplace of top-tier experts.
View benchmarks
Data, evals, and post-training at the frontier
Mercor is used by the top 5 AI labs and 6 of the Mag 7.
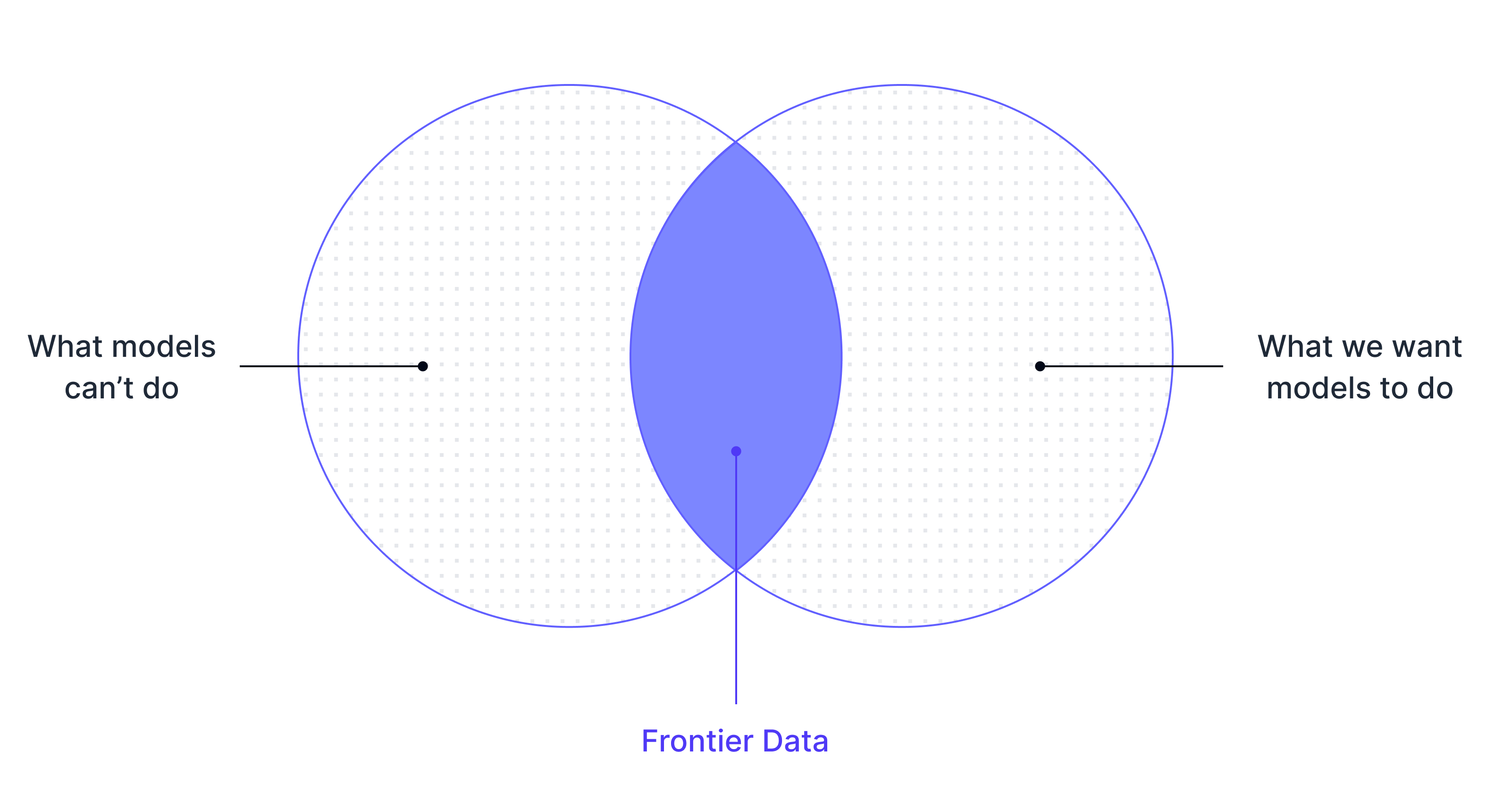
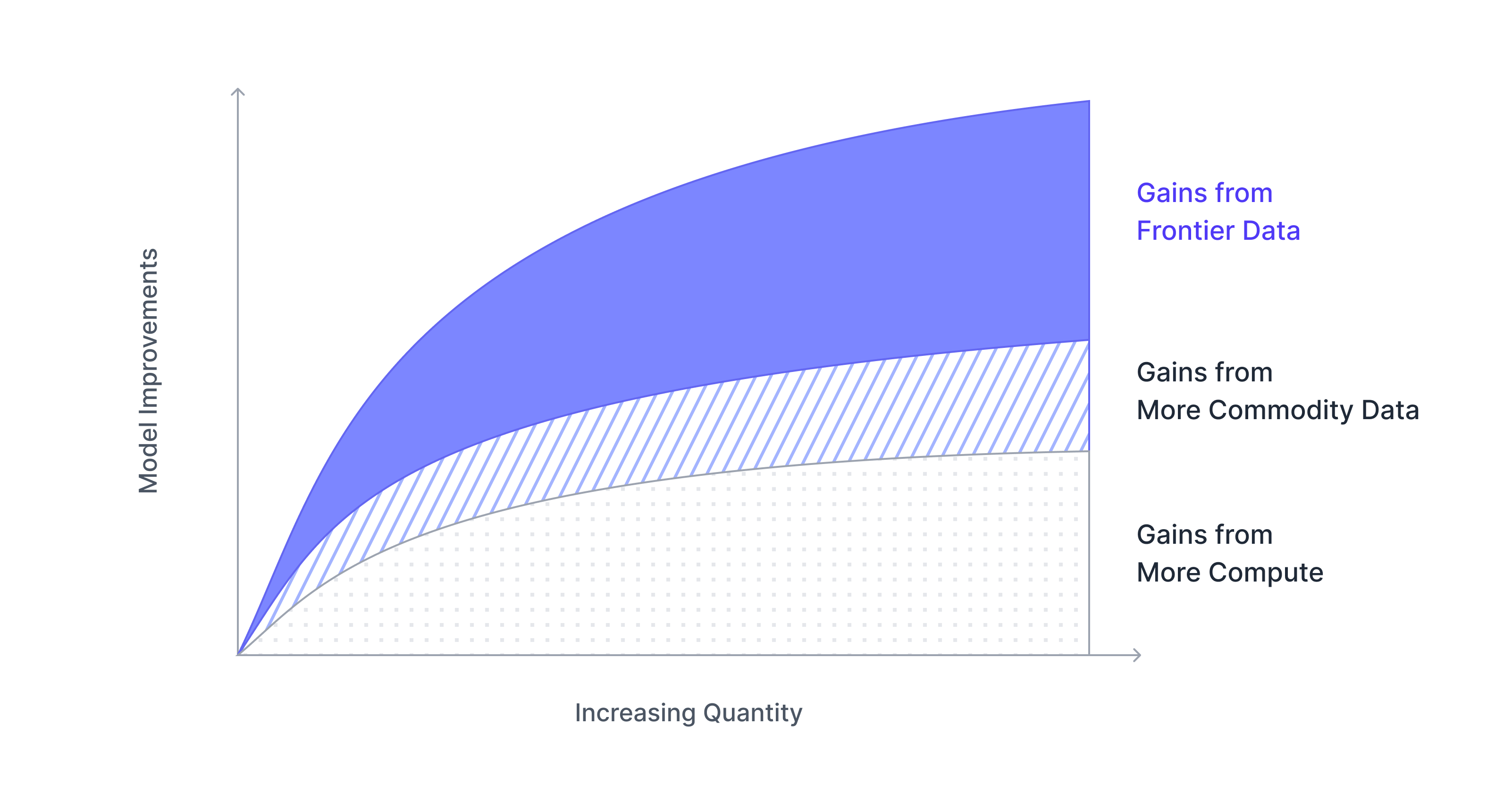
When model capabilities reach their limits, progress depends on data quality. Mercor's talent platform mobilizes deep subject-matter experts across professional and consumer domains to produce specialized data at scale.
Frontier-grade data unlocks advanced reasoning, long-horizon planning, tool use, and safe behavior under uncertainty. We power meaningful gains with novel datasets that are realistic, challenging, and diverse.
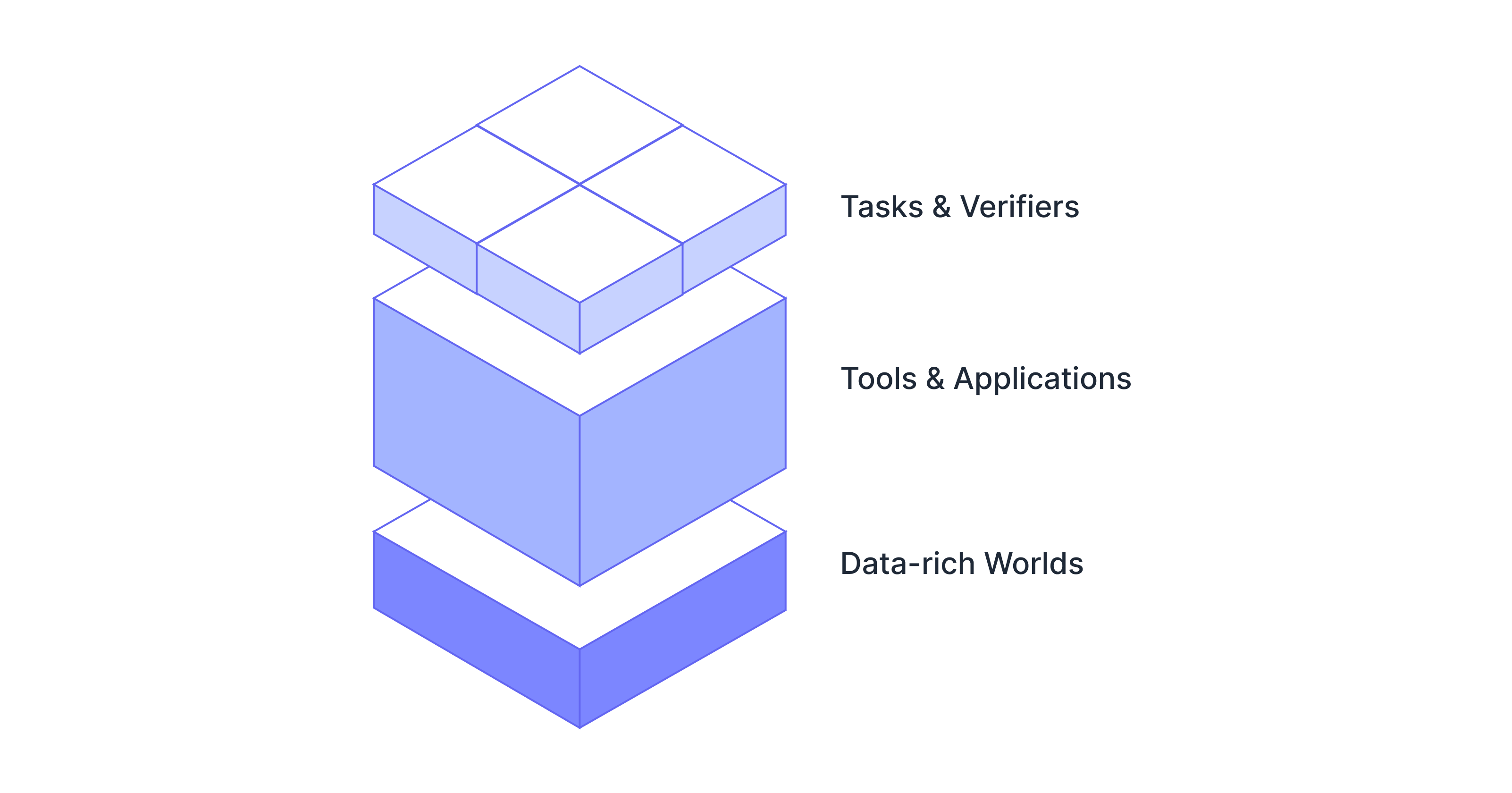
We build reinforcement learning (RL) environments in three steps: creating realistic data-rich worlds that capture real behavior, implementing the tools and applications that agents need to interact with the world, and making rigorous tasks and verifiers.
Benchmarks
Benchmarks, peer-reviewed research, evaluation leaderboards, datasets, and open tooling for frontier AI systems.
APEX-Agents
The AI Productivity Index for Agents (APEX-Agents) measures whether frontier AI agents can execute long-horizon, cross-application tasks across three jobs in professional services.

GPT 5.4 (xHigh)
36% ± 3.8%
GPT 5.2 (xHigh)
34.4% ± 3.8%

Gemini 3.1 Pro (High)
33.5% ± 3.6%
APEX
The AI Productivity Index (APEX) assesses whether frontier models are capable of performing economically valuable tasks across four jobs: investment banking associate, management consultant, big law associate, and primary care physician (MD).
GPT 5.4 (High)
67.2% ± 2.4%

Opus 4.6 (Max)
65.7% ± 2.6%
Opus 4.6 (High)
65.3% ± 2.7%
ACE
The AI Consumer Index (ACE) assesses whether frontier AI models can perform everyday consumer tasks in shopping, food, gaming, and DIY.
GPT 5 (High)
56.1% ± 3.3%
o3 Pro (High)
55.2% ± 3.2%
GPT 5.1 (High)
55.1% ± 3.2%
APEX-SWE
The AI Productivity Index for Software Engineers (APEX-SWE) measures whether frontier AI systems can execute economically valuable software engineering work. It covers Integration and Observability tasks.
GPT 5.3 Codex (High)
41.5% ± 6.25%
Opus 4.6 (High)
40.5% ± 6.34%
Opus 4.5 (High)
38.7% ± 6.34%
Mercor blog
Read our latest insights in frontier data and AI research.

Introducing the AI Productivity Index for software engineering
A new benchmark that measures whether frontier AI models can handle real software engineering work
Mar 24, 2026

Introducing APEX-Agents
Our new benchmark designed to test how well AI agents complete real, long-horizon tasks in investment banking, consulting, and corporate law.
Jan 21, 2026

Expanding the AI Productivity Index (APEX)
Bridging the gap between AI evaluation and economic value
Dec 10, 2025

The Economy will become an RL environment
The market for humans teaching models is based on the amount of tasks humans can't do.
Sep 15, 2025
Opportunities
We're looking for exceptional people to join our Research and Engineering team.
View All Openings