Types of Data
There are many steps to training large language models — and their derivative systems, like agents — with many types of relevant data involved.
This isn’t a checklist of sequential steps you have to complete to get from a raw, unaligned model to a fully autonomous AI agent. It’s more of an overview of common training processes and the data workflows involved.
Pre-training
Pre-training involves feeding the model vast amounts of unstructured data to learn the structure and nuances of the language(s) in the dataset. The model predicts parts of the data withheld from it, and its parameters are updated based on a loss function, which measures prediction errors. This step is typically performed using diverse sources like web pages, books, conversations, scientific articles, and code repositories. Two commonly used locations of pertaining data are “Common Crawl” and “The Pile”.
You generally won’t involve expert annotators directly in creating this data, though they can help with curation. There are exceptions, like in this paper which explores using human preferences in pre-training data.
Supervised fine-tuning (SFT)
Supervised fine-tuning (SFT) trains the LLM on labeled datasets of input-output pairs for specific tasks, enhancing performance in those areas. However, extensive fine-tuning may trade off generalization capabilities for specialized task performance.
An example prompt-response pair for arithmetic:
- Prompt: Calculate the sum of 66231613267717 and 60882409809.
- Response: 66231613267717 + 60882409809 = 66292495677526
Prompt-response pairs don’t always need to have an objective right answer, though, the same technique can be applied to function calling, agent planning, or even writing amazing bedtime stories for children.
Especially when trying to improve model performance in a particular task, it’s critical to (1) ensure the pairs are high quality and (2) select for data at or beyond the frontier of current model capabilities. While you can use synthetic data for this purpose, you’ll likely need to work with human experts when you want to push beyond current frontier model capabilities and collect out-of-distribution data.
Instruction fine-tuning
Instruction fine-tuning is a specific type of SFT that teaches the model to follow specific prompt instructions. OpenAI used this method to align their InstructGPT models to be much better at following human instructions than the original GPT-3 model.
You can work with a team of human annotators to create instruction prompt-response pairs across the instruction-following use cases you care about. For example, OpenAI used the following instruction types: Generation, Open QA, Brainstorming, Chat, Rewrite, Summarization, Classification, Closed QA, and Extraction.
Creating instruction prompt-response pairs often involves human annotators, though many open-source instruction datasets are now available.
Especially when trying to improve model performance in a particular task, it’s critical to (1) ensure the pairs are high quality and (2) select for data at or beyond the frontier of current model capabilities. While you can use synthetic data for this purpose, you’ll likely need to work with human experts when you want to push beyond current frontier model capabilities and collect out-of-distribution data.
Parameter-Efficient Fine-Tuning (PEFT)
PEFT techniques aim to make it much more efficient to fine-tune models by adjusting a smaller number of parameters. One common PEFT technique is Low-Rank Adaptation (LoRA).
PEFT techniques still involve using prompt-response pairs to fine-tune the model.
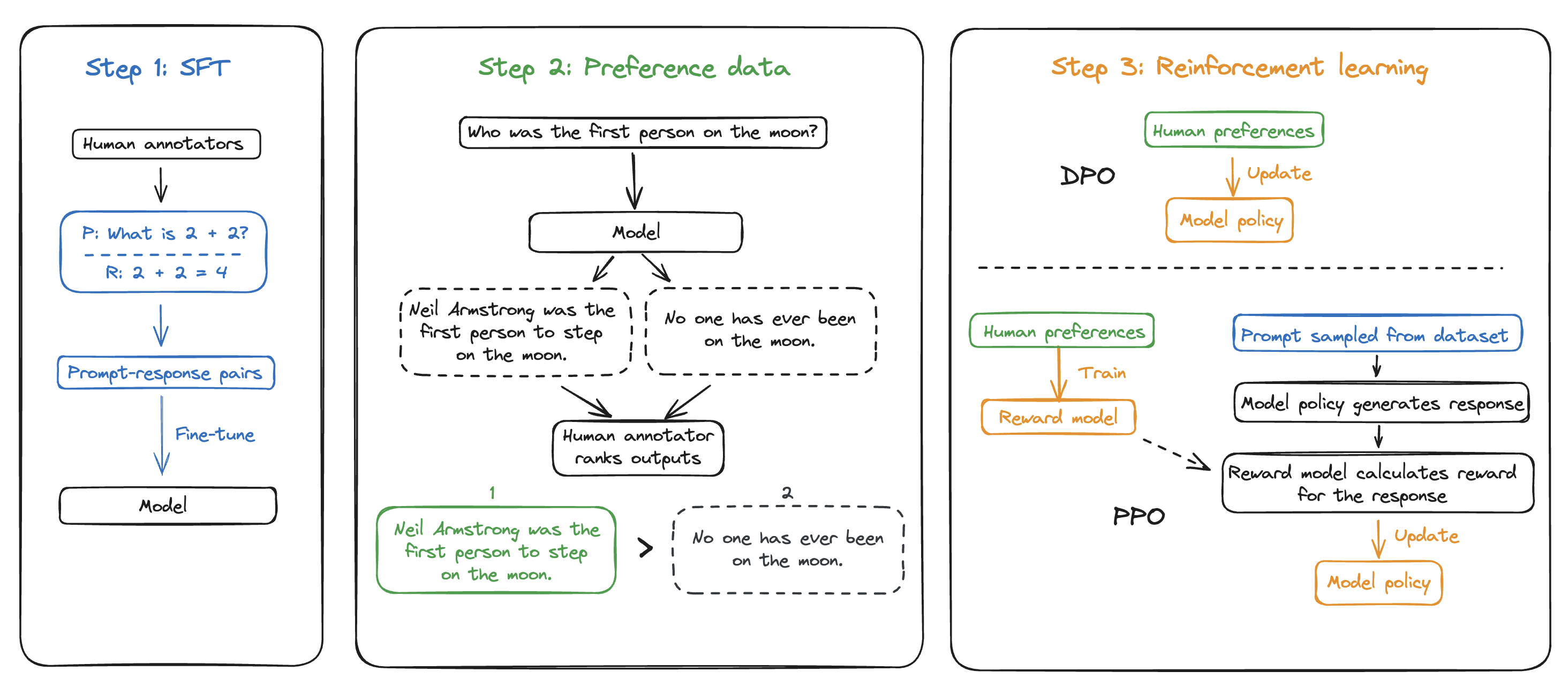
Reinforcement learning with human feedback (RLHF)
RLHF is a form of fine-tuning that aligns model outputs with human preferences. At a high level, it involves having humans rate model outputs on certain prompts, and using those rating signals to fine-tune the model to generate more aligned outputs. It often follows an SFT stage.
The RLHF training process has two primary steps:
- Have the model generate multiple outputs for a given prompt, and have humans rank these outputs based on their preference. This forms a set of preferred prompt-response pairs. Preferences are typically measured on a Likert scale from 1-7 and can be broken out by specific qualities you want the model to prefer, such as helpfulness, correctness, and style.
- Use the pairs to do one of the following:
- Train a reward model (a model to replicate human preference), which is then used to update the target model’s policy (the strategy used to generate responses), using an algorithm like proximal policy optimization (PPO).
- Or directly adjust the model’s policy with the human preference data. This is called Direct Preference Optimization (DPO), a newer approach that simplifies the process.
RLHF can be complicated, expensive, and finicky. Many organizations don’t have the resources needed to do it well, and it may not even be needed for many application-specific use cases.
How do I know if it’s working? Enter evals
Training a model can be quite expensive between the compute and data costs. It’s important to know if your model is actually improving in the areas you care about.
One way to do this is to use a set of evaluation tasks, or evals, to measure your model’s performance in specific capabilities. Evals would contain a question/prompt and a correct answer (or a way to at least know the answer is correct in the case of more subjective answers), against which we can compare the model’s answer to the prompt.
You can and should evaluate your model at each stage of fine-tuning to understand how effective your methods and datasets are.
There are a few major challenges with model evaluations:
- Public benchmarks used to evaluate model performance (MMLU, GSM8K, HumanEval, Chatbot Arena) are not sufficient to measure application-specific performance. Additionally, open benchmarks can sneakily contaminate your model via training data.
- Your eval set needs to cover all of your actual use cases, be sufficiently challenging, and be accurate. As models get better, you’ll need more and more task expertise to create high-quality eval sets.
- Not all tasks can be automatically evaluated, so you might need human experts in the loop to evaluate results.
In an ideal world, you have a comprehensive, high-quality eval set, and use it as a ground truth to judge dataset effectiveness whenever you fine-tune your model. We often recommend creating this eval set before you even start fine-tuning, so you can measure performance improvements.
The alternative is to do model ranking, with humans comparing post-fine-tuning model outputs vs other model outputs (including your own model before fine-tuning).
Good evals may seem expensive, but it’s a lot cheaper in the long run than flying blind when it comes to real-world model performance.
Data across workflows and modalities
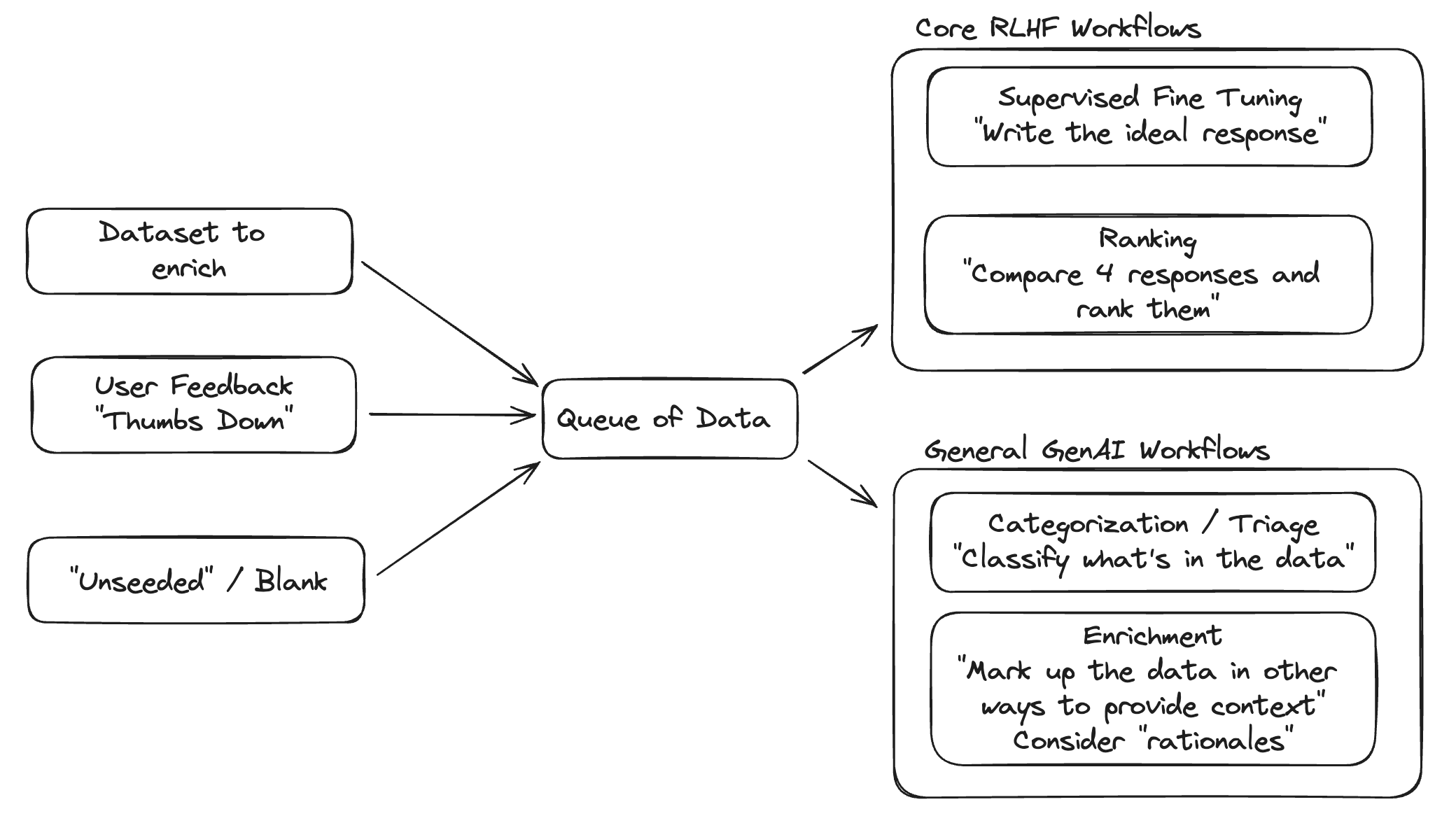
This is quite general, but one way to look at categories of data is to break them down by:
- What the data will be used for (SFT, RLHF, evals, etc.)
- The format of the data itself (prompt-response pairs, ranking, reasoning, etc.)
- The domain/focus area of the data
As seen in the above diagram, you might intake data from sources like external datasets or in-application user feedback, and use it across different fine-tuning or evaluation workflows. Let’s go through some common data flows.
Conversational data
Conversational data is useful for fine-tuning your LLM to interact with humans. You can collect input data from user sessions with a chatbot, public chatbot/conversational datasets, or by having annotators create them from scratch.
Conversations can be single-turn or multi-turn:
- Single-turn: each conversation consists of a single prompt and response, without further context. It can be a good starting point when fine-tuning your model.
- Examples: trivia questions, simple programming tasks, translations
- Multi-turn: each conversation consists of multiple turns of back-and-forth discussions between parties. Multi-turn data is great for learning more realistic conversation patterns, but is more complex to collect, annotate, and train on.
- Examples: customer support logs, chatbot interactions, roleplaying dialogues
You can first have annotators create conversational data (e.g. instruction response pairs) from scratch to fine-tune your model. When your model is deployed, you can surface multiple responses during user conversations, ask users to select preferred responses with reasoning, and use this data for RLHF (after triaging to filter for valuable, high-quality data).
Agentic flows
Agentic workflows involve deploying LLMs as part of a system to autonomously plan and execute tasks. Agents can break down high-level tasks into plans, execute on steps, interface with external tools, and even collaborate with humans and other agents.
Here are some types of data you might collect and use to improve your agent:
- Planning data: Improve the LLM’s capability to plan out workflows. This can look like breaking down directives into steps, updating plans based on task results, assigning work to agents, and self-reflecting.
- Task-specific data: Fine-tune the LLM to perform better at specific tasks it will handle. Examples can include using external tools, writing code, and summarizing inputs.
- Multi-turn conversation data: Train on long conversations to maintain coherence when interacting with humans or other agents.
- User preference data: If your agent is directly user-facing, you can have the user select preferred outputs, either at each step or the end of a workflow.
Your agent will collect a lot of data that’s out of your training data distribution once launched. It’s key to collect and triage this data. It can be used as the backbone for debugging your agent, fine-tuning your underlying model, and creating evals for both the model and system:
- Create SFT data for agent runs that failed due to incorrect model outputs. This way, you can improve the underlying model’s capability to perform core tasks, like planning, using tools, or having conversations.
- Create model evals from agent runs that failed due to incorrect model outputs. These model evals will test your model’s ability to execute on specific steps.
- Since workflows can involve many sequential steps, and mistakes will compound downstream, it’s particularly important to have good evals to evaluate each major step.
- Create system evals from agent runs that failed due to overall system failures. These are useful to understand if your system performs consistently on specific workflows.
- Collect user preference data on step-by-step or workflow outputs, and use this for RLHF to align your underlying model with human preferences on helpfulness, accuracy, and safety.
Multimodal (image, video, audio)
When working with multimodal data, you may encounter various data flows. Sources for multimodal data can include public datasets (e.g., YouTube-8M), user data collected in your application, compilations of data found online, and net new multimodal data created by annotators.
Image data
Pre-processing steps involve resizing, normalization, and augmentation techniques like rotation, flipping, and cropping to increase data diversity. Annotation processes include:
- Classification: Assigning a label to an entire image (e.g., hot dog or not hot dog).
- Captioning: Creating descriptive sentences about the content of an image.
- Object Detection: Identifying and labeling objects within an image with bounding boxes.
- Segmentation: Classifying each pixel of an image into categories.
For generative AI applications, there are two primary workflows involving humans:
- Captioning images to improve the representation of images to the model
- Having conversations with or about images to teach the model how to extract information from images and use it to generate a response.
Video data
Pre-processing can involve frame extraction, temporal segmentation, and potentially downsampling to manage large file sizes. Classic annotation processes can include:
- Action Recognition: Labeling actions occurring in a video (e.g., walking, running).
- Event Detection: Identifying specific events within a video sequence.
- Tracking: Following objects or persons across frames in a video.
- Captioning: Writing descriptions for video segments, including actions and events.
Video’s GenAI workflows involving humans are quite similar to images.
Audio data
You might pre-process audio data with steps like noise reduction and normalization. Annotation processes can include:
- Speech Transcription: Transcribing spoken words into text.
- Speaker Identification: Recognizing and labeling different speakers in an audio clip.
- Speech Synthesis: Generating natural-sounding speech from text input.
Language fluency is a common annotator requirement for handling audio speech data.
For GenAI applications, creating audio data can involve collecting representative audio samples covering use cases, domains, and the range of emotions and vocal expressions you want to incorporate into your product.
A key point is that handling multimodal data often requires distinct tooling, labeling pipelines, and specialized annotator teams.