Building a Best-in-Class Data Pipeline
Regardless of where you are right now in terms of readiness or sophistication, it can be helpful to take a few minutes and review how the world’s leading AI labs and data annotation vendors are constructing their data annotation pipelines today.
You by no means need all of these components to get started, but we hope that by seeing what’s around the corner, you’ll be able to take small steps towards a more scalable future.
While not technical, we’ll be getting fairly far into the weeds of how annotation processes are represented in the labeling platforms and why.
Structuring the work
Tasks, Subtasks, Task Stages, Batches, Campaigns, Projects, oh my...
At a high level, we recommend breaking out the work to be done in the structure below. Having a clean and consistent structure makes everything so much easier to manage. Every team and company will use slightly different vocabulary for these structures, but the overall concepts should remain the same.
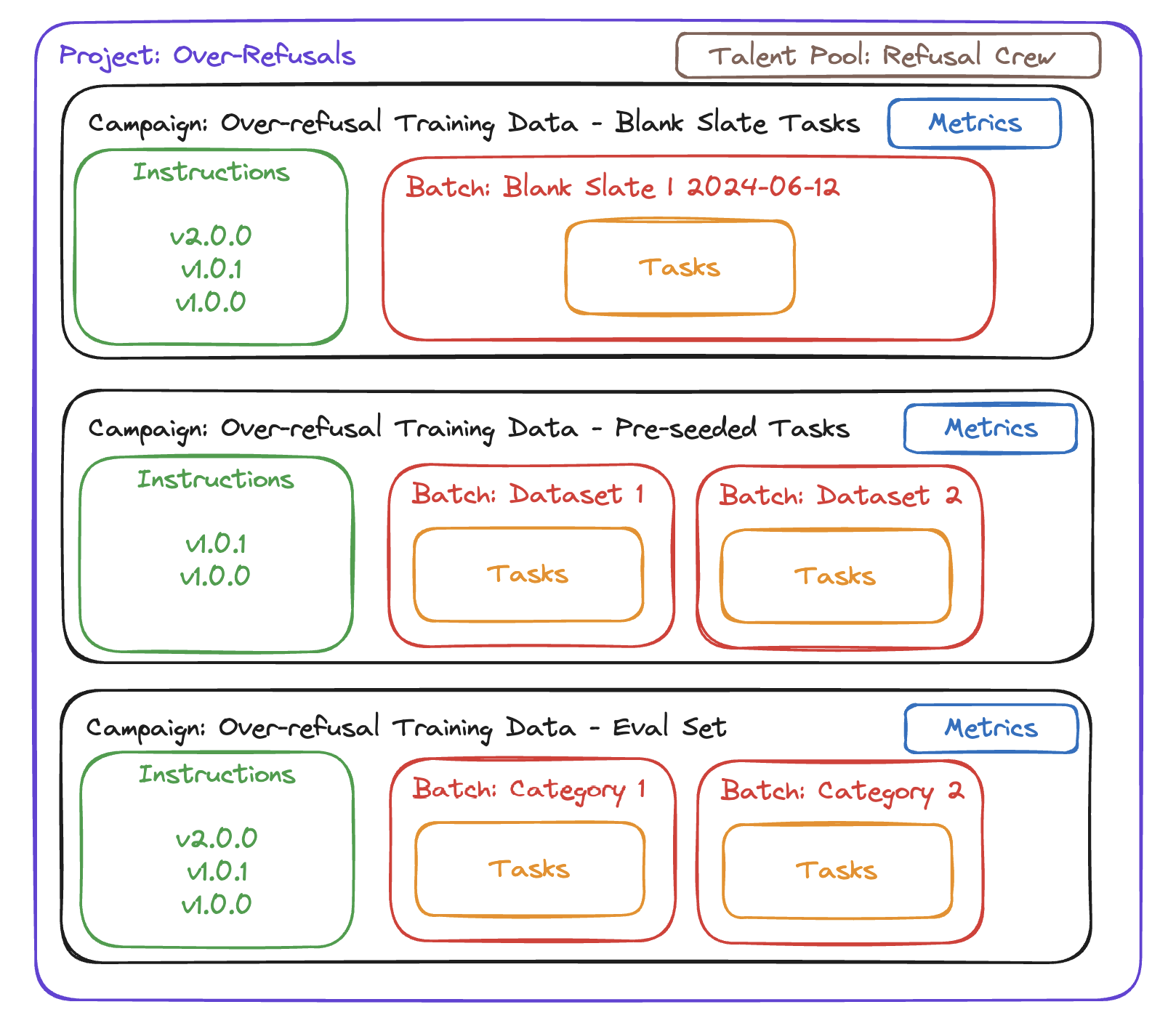
Building blocks
Projects
Projects are the highest level of organization and can be thought of as a single initiative that a group of annotators with shared expertise will work on.
The work to be done in a project is similar in nature, but may be broken out into several different campaigns that start and stop at different points, with slightly different goals, instructions, and work to be done.
Projects should be used to assign a pool of talent, so you don’t need to pull your hair out micro-managing adding and removing people from 10 different campaigns each time a personnel change happens.
Tracking metrics and setting goals at the project level is pretty challenging, because the quality bar, time per task, and work to be done can all be very different within each campaign.
Early on, projects may look like a shared Google Drive folder consisting of the different campaign trackers, instructions, and guidance on the nature of the work.
Campaigns
Campaigns should group together similar work, where the instructions and work to be done will not meaningfully change. If big changes are needed to the instructions or the way the task is completed, it’s best to put that in a new campaign.
Metrics, including throughput and quality goals, should be set and measured at the campaign level. Because we want to have at least a somewhat “Apples to Apples” comparison over time, it’s important that we don’t wildly switch up what’s going on within a campaign.
Instructions should be set at a per-campaign level. Your instructions are going to change as time goes on and you collect more feedback and edge cases. I highly encourage instructions to be versioned so you can honestly state what the expectations and guidance were at the time a given set of data was labeled. Data staleness is real, and wondering why a bunch of “off-policy” data is still in the training dataset has bitten many a team.
Candidly, there’s a bit of a balancing act between re-using parts of the instructions across campaigns within a given project. There’s not a great way of doing this in 2024 I’ve found without dedicated tooling, but with the right annotation tooling, instruction component reuse AND versioning do exist harmoniously.
Batches
For larger campaigns, it can be helpful to further subdivide a campaign into batches.
Some common ways people group tasks into batches are:
- Diversity group or use case - It’s a best practice to have a strong opinion about the diversity of data you want collected. Creating batches with a set number of tasks to do is one way to set clear expectations and measure progress on different use cases
- Dataset origin - If you are creating tasks to enrich an existing dataset or evaluation, making a batch per dataset with the number of tasks you want to be completed from each can make sense
- Model version - If you collect user data from a model that you want to annotate, clearly storing the model version or snapshot used can be a way to ensure you are only labeling “on-policy” and recent data and setting expectations about what to do with older data.
- Creation date - If you have a long-running campaign of very similar work, dividing it by the week or month it was created allows you to compare cohorts of data over time.
- Instruction version - This can be a bit duplicative and we generally recommend keeping instruction versions separate from batches, but some view dividing campaign batches into instruction groups as a way to ensure only helpful, “on-policy” data is being collected.
One of the more common issues annotation teams face is how to close out batches of data. Oftentimes, there will be a long tail of data that is hard to finish for whatever reason. Setting clear expectations about how to close out batches and when to start new ones with any labeling team or vendor is very important. Sometimes getting 100% completion is really important, but other times closing the batch at less than 100% completion is easier, faster, and preferred. If closing out batches early, you need to watch out for “cherrypicking”, where annotators only do the easy tasks and you never get the diversity or complex cases you had in mind completed.
Tasks
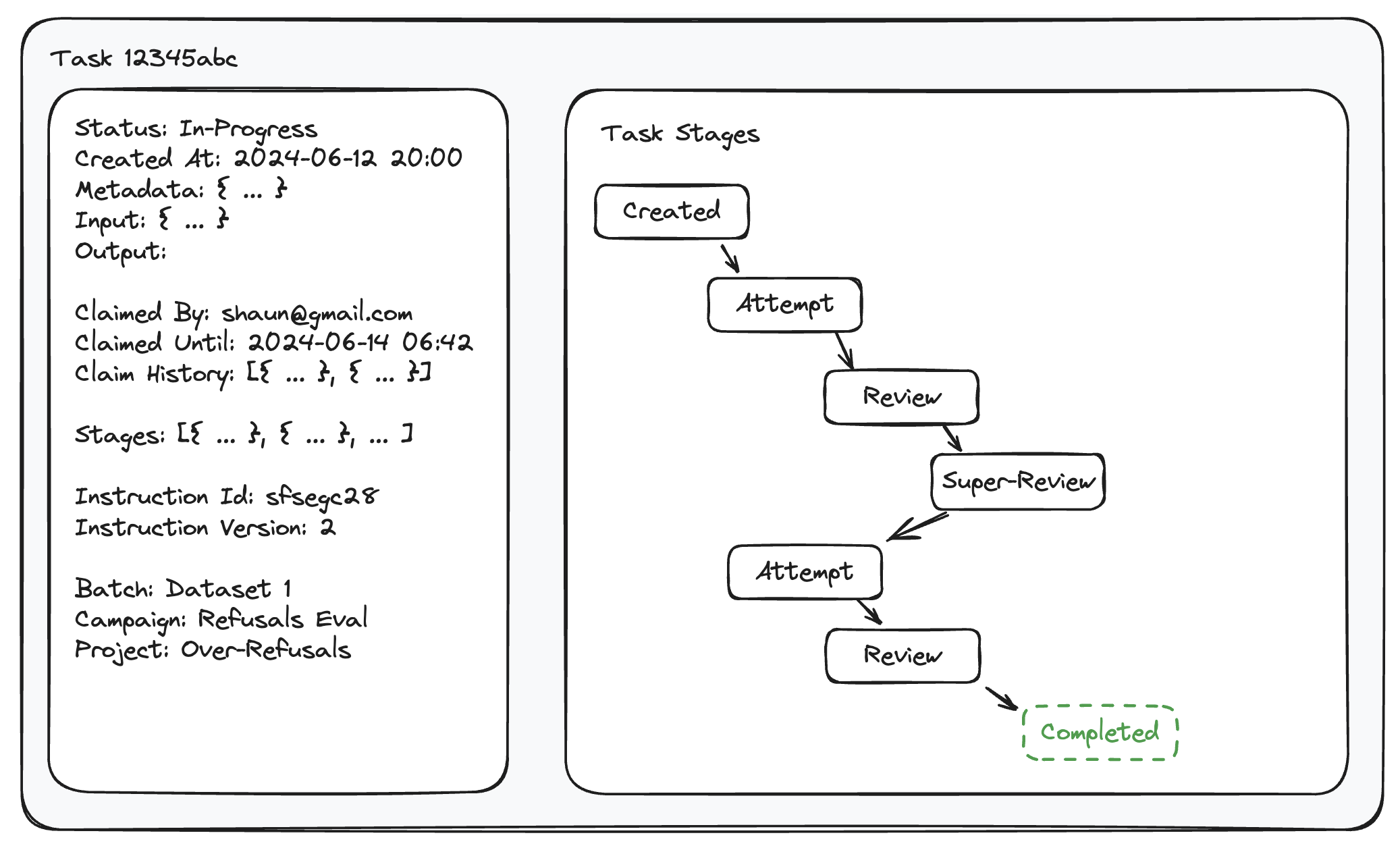
A task represents the unit of work to be completed.
Inputs and Outputs
The input of a task, or the work to be done, is fixed and doesn't change, while the output gets updated as the task goes through its different stages.
Task Statuses
Tasks have a task status. Task statuses usually include at least
- Todo / Unstarted - A task that has not been picked up for work
- Completed - A task that is ready for data ingestion
Some types of task statuses are more open-ended, such as how to track in-progress work and how to represent the status of reviews.
Our recommendation is to add an “in progress” task status representing that somebody has picked up the task and it is being worked on. This gets into the idea of task “claims”, in other words, how does someone indicate that they will be or are working on a given task?
Tracking the task review status can be especially tricky, as tasks may have no reviews and still be ingested, or a single review, or multiple reviews. Heck, tasks can even be reviewed, restarted, and then reviewed again. Our recommendation is to track reviews (and current task stage) independently of the task status.
An additional nuance on task status is how one marks a task as “Ready for Ingestion”. It can be the case that the annotator has finished the work but it hasn’t been reviewed by a team lead, or the annotator is new and before the client sees the work, we want to spot-check that person to ensure their work can be trusted. “Ready for ingestion” can be its own task status, a task stage, or a stand-alone field on the task that can be filtered.
Metrics
Storing things like time per task or accuracy at a task level can be tricky. What happens if we want to redo the annotation? Does accuracy reflect the state of the first attempt, the latest review that was reviewed by someone else, or something else? A lot of task metrics will make more sense to capture at a per-stage level, and then can be thoughtfully rolled up and summarized at the task level.
Metadata
Task metadata is a great place to store information that makes working with the data after it’s annotated much easier. Metadata typically includes the source of the data and anything that’s going to help you pair up the annotation with the rest of the system you want to plug the data into. When creating net new data from scratch, there may not be much metadata compared to annotating an existing set of data, say, from a data collection flywheel.
Instruction Version
Since your instructions are going to change as you execute your campaign, knowing what the instructions looked like at the time the task was completed can be helpful for filtering which data you want to include, or which data you want to do a targeted update for.
Task Claims
Letting annotators claim tasks they are working on, and assigning tasks to people are important parts of the labeling workflow. This can be accomplished by having a claimed_by and a claimed_until property on the task. Claims can be set when an annotator picks up a task, or they can be assigned in advance to allow only that specific person to pick up the task. The length of the claimed_until period is based on how long the task takes to do, how much work is lost if another person restarts the work, and how consistently annotators log in or engage with the platform.
It’s usually a best practice to also set a claimed_limit of say, 5-10, at the campaign level so that folks can’t just take all of the easy tasks and leave their peers with the hard ones.
Task Stages
In order to have accurate metrics for quality and throughput, it’s important that the tracking for the work done is immutable.
In its most basic form, a corrected task will simply overwrite the output that the previous person created. The challenge is that any feedback, issues with accuracy, proof of work, or error categories now become disconnected from the current task state.
Even on the earliest parts of the sophistication curve, the output from the “attempt” stage must be locked and not changed as reviews are completed. In this simple form, you would have two stages, an “attempt” stage and a “review” stage. This simple bifurcation gets you pretty far, but it stops working if you want to verify reviews with a review, or send tasks back to the “attempt” stage to be re-worked, and then reviewed again. Redoing tasks and verifying reviews is a pretty common thing you’ll want to do.
We highly recommend adopting a graph approach to task stages and creating a new node each time someone edits (or even looks at, ideally) the task.
Inputs and Outputs
Each stage has an immutable input and, once the work is done, an immutable output.
The input should be the output from the previous stage node if one exists.
Metrics
Task stages are a great place to store lots of metrics, metrics could include the time taken and quality metrics populated from the review of that specific pipeline stage. Task stages are where we want to track all of the actual human work done on the task.
Make sure to track who is doing the work on each specific stage.
Types of Stages
Common task stages include:
- Created
- Attempt
- “Standard Review”
- “Super Review” (Maybe a team lead responsible for managing the reviewers)
- “Employee Review” (When a researcher or client staff is doing the review)
- Complete or “Ready to Use” (can accept tasks from all or some previous stages)
Subtasks
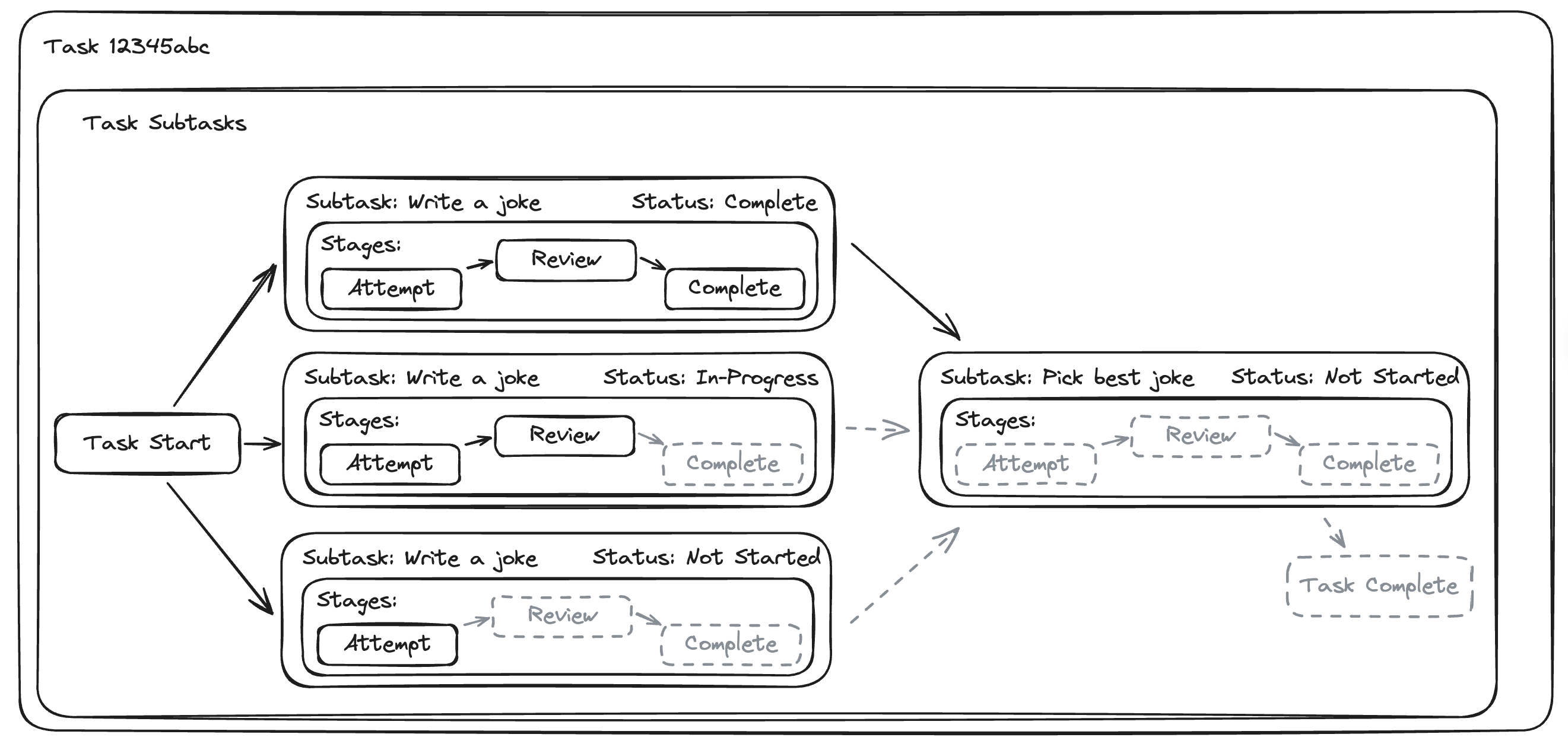
Some types of tasks can be especially complex, such as when you want to use a consensus model to determine the right output, break out a very time-consuming task into smaller pieces, or have multiple people contribute to producing an output that should be reviewed as a whole.
In cases such as these, you can duplicate the ideas of task stages and task statuses on the subtask, and have the task stage and status be updated based on the statuses of all of the child subtasks (for example, the task becomes complete when all subtask’s task statuses move to complete).
Subtasks, like task stages, are broken out into a graph and can be dynamically created.
If you think you’ll need subtasks in your life, you can support one task type that has a 1:1 mapping of task <> subtask, and another task type that supports the complexity of splitting and merging work across subtasks.
Inputs and Outputs
Each stage has an immutable input and, once the work is done, an immutable output.
The input should be the output from the previous stage node if one exists.
Metrics
Task stages are a great place to store lots of metrics, metrics could include the time taken and quality metrics populated from the review of that specific pipeline stage. Task stages are where we want to track all of the actual human work done on the task.
Make sure to track who is doing the work on each specific stage.
Types of Stages
Common task stages include:
- Created
- Attempt
- “Standard Review”
- “Super Review” (Maybe a team lead responsible for managing the reviewers)
- “Employee Review” (When a researcher or client staff is doing the review)
- Complete or “Ready to Use” (can accept tasks from all or some previous stages)
Putting it all together
Implementing a structured, scalable data pipeline not only enhances the efficiency and quality of your data annotation processes, but it also positions your team to adapt swiftly to evolving project requirements and complexities.
By leveraging the concepts of projects, campaigns, batches, tasks, subtasks, and stages, you create a flexible yet robust framework. This framework helps ensure that every piece of work is tracked, managed, and reviewed systematically. The ultimate goal is to maintain high standards of quality and efficiency while minimizing bottlenecks and errors.
While there can be a lot of components to consider about how to best organize the data within an annotation platform, it’s important that you build to meet your needs. As you continue to refine your data pipeline, remember that the key to success lies in iteration and adaptation. Regularly review your processes, solicit feedback from your team, and stay informed about industry best practices. With a well-structured approach, your data annotation efforts will become much more manageable!
We hope this guide has provided valuable insights and actionable strategies to help you build a best-in-class data pipeline - we’d love to chat more about this with you!