Introducing APEX:
The AI Productivity Index
The AI Productivity Index



The biggest obstacle to AI delivering on its economic potential is the gap between existing AI evaluations and what professionals do in the real world. We're launching the AI Productivity Index (APEX) to start bridging this gap.
APEX is a first-of-its-kind benchmark that evaluates AI models based on their ability to perform economically valuable knowledge work. With future releases, we will expand coverage to other industries, roles, and countries.
APEX is gauging how AI systems are increasing productivity, reshaping the workforce and creating economic value. Alongside other initiatives in the research community, such as OpenAI’s GDPval, we are proud to guide the development of the next generation of AI models to make them more useful. AI is already superhuman at Olympiad math, but these capabilities can be disconnected from what drives the economy. It's great to have 10,000 PhDs in your pocket—it's even better to have a model that can reliably do your taxes.
Constructing APEX
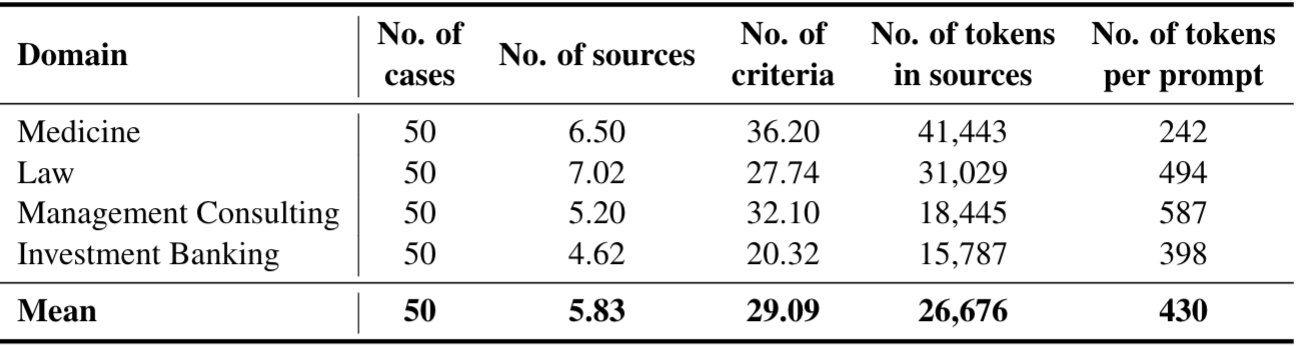
APEX v1.0 consists of 200 cases split evenly across investment banking, law, consulting, and medical practice. Each case consists of a prompt (task description), sources (information needed to complete the task), and a rubric (criteria for grading model responses). We constructed APEX v1.0 in five steps:
- Sourcing experts: we assembled a team of ~100 experts with top-tier experience (e.g., investment bankers from Goldman Sachs) across four professions.
- Prompt generation: experts generate task descriptions, or prompts, describing common workflows in each domain. These workflows are aligned with economic value creation in two ways. Tasks are based on deliverables: prompts ask models to generate deliverables, e.g., a patient diagnosis by a doctor or a competitive research memo by a consultant. Thus, each task in APEX, if completed, would generate genuine economic value. Task distributions: the distribution of prompts exactly matches the experts' estimate of the share of time spent on each workflow. For example, in investment banking, financial modeling and valuation (FMV) tasks were estimated to take up 30% of analysts' time. Thus, FMV tasks comprise 30% of the APEX investment banking benchmark.
- Source generation: experts produce source documents that contain relevant evidence needed to respond to the prompts. For example, in medical practice, a source document might be a real or synthetic set of CDC recommendations. On average, each prompt is accompanied by 5.83 source documents, comprising (on average) 26,000 tokens.
- Rubric generation: experts produce a rubric of prompt-specific criteria. Each criterion is an objective and self-contained statement about the response. For example, if the prompt asks the model to analyze growth opportunities for Delta airlines in 2025, one criterion could stipulate "the response mentions Delta airline's 2025 revenue." Rubrics have an average of 29.09 separate criteria.
- Quality control: After prompts, sources, and rubrics have been generated by an expert, a separate expert reviews them to ensure quality control. In total, 300 prompts were started by contributors, of which 200 were approved by reviewers and added to APEX v1.0.
Experts estimated that tasks in APEX would take a professional between 1 and 8 hours (3.5 on average).
Evaluation & Results
We evaluate 21 state-of-the-art models using APEX v1.0, including top-performing closed and open source models. Each model is given the prompt and sources as an input, and then outputs its response as long-form text. The text responses are graded by a panel of LLM judges (majority vote) according to the expert-generated rubric. The overall score for each response is defined as the average number of criteria satisfied.
This rubric-based evaluation system–also used in OpenAI’s excellent HealthBench work–allows us to automatically grade new models as they are released while maintaining consistency and objectivity. We report our findings on auto-grading consistency in our white paper.
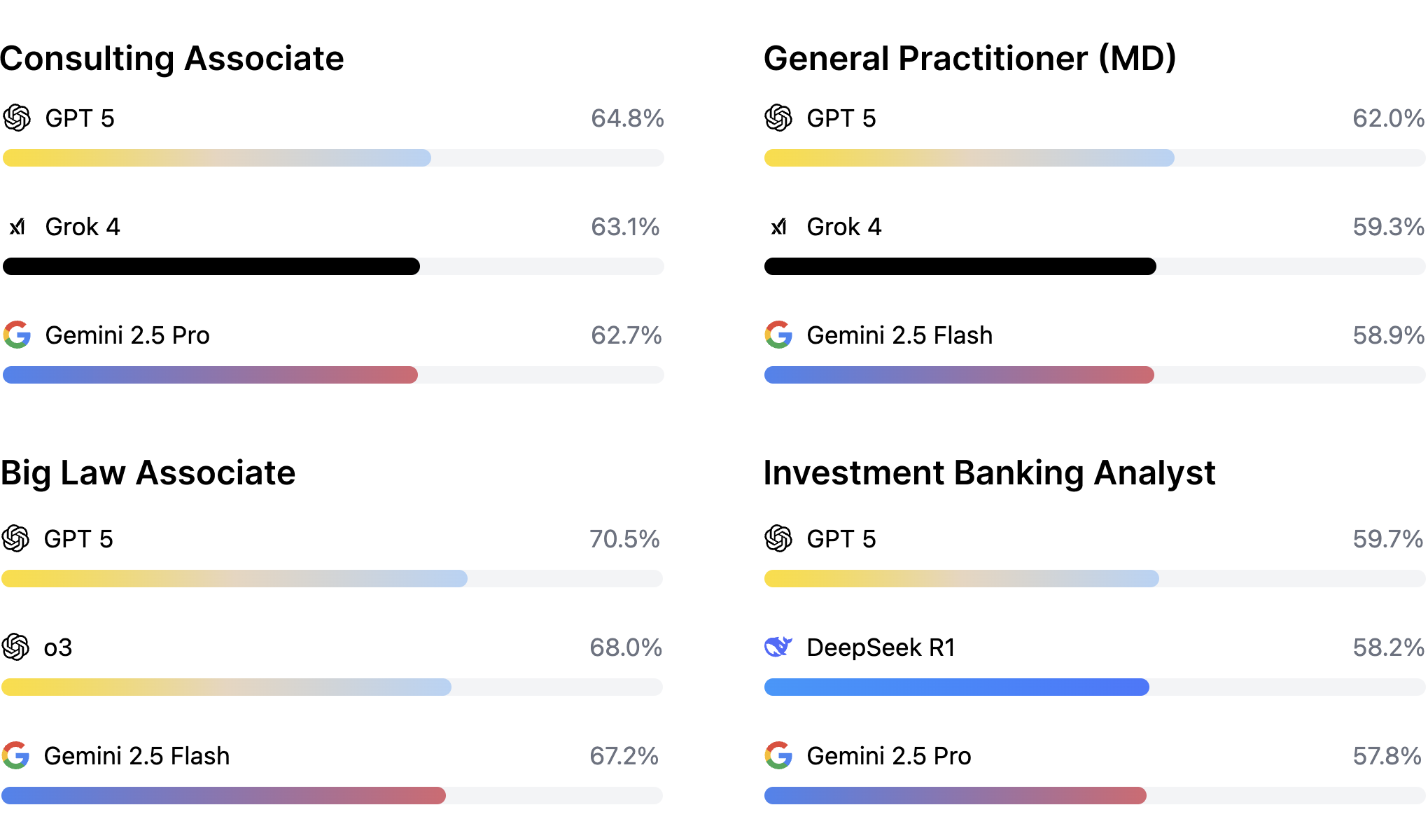
GPT-5 achieved the top score of 64.2% and the best performing open source model, Qwen3, was ranked 7th overall with 59.8%. The top scores were highest in Law (70.5%) and worst for Investment Banking (59.7% ). None of the models meet the production bar for automating real-world tasks in the four professions we looked at. In a live setting, all would require substantial human oversight.
That said, the initial results provide a basis for optimism. APEX-v1.0 is highly complex, and its tasks require advanced reasoning, synthesis, multi-hop knowledge handling, and expert-level critical-thinking. This is reflected in the time that annotators estimated it would take them to complete the tasks (3.5 hour average). Models that could autonomously complete these tasks have the potential to unlock hundreds of billions of dollars of value across the U.S. economy.
Future work
APEX-v1.0 represents a step forward towards economically meaningful evaluations of AI models. However, it is an imperfect benchmark, and we plan to improve APEX over time:
APEX world: We are working on introducing simulated environments to allow AI models to interact with clones of common applications like SharePoint, Google Workspace, and other external tools via MCP, API, and GUI. We are hiring experts to populate these worlds with data as if they are working in mock companies. Future iterations of APEX will then evaluate models' ability to interact in these worlds, with many more tools and files available to the models. We aim to bridge the sim2real gap in world fidelity, data distribution, and task realism.
Expanding the benchmark: We will broaden the range of professions and task types included, particularly in creative and technical fields. In partnership with academic and industry leaders, we will increase the granularity of the first four domains to show results in specific groups of workflows and areas of practice.
What does 60% mean? No models are close to achieving a 100% score on APEX. That said, in some cases, a performance of 60% may already add substantial economic value–for example, perhaps a consultant can more easily complete a competitor analysis if given an initial draft from an AI. On the other hand, in some domains, inaccuracies may be actively harmful–an AI-generated diagnostic report might ultimately waste a doctor's time if it needs to be carefully fact-checked for inaccuracies before it can be used. More research is needed to understand the economic impact of imperfect models.
For questions, feedback, or to get involved, reach out to us at [email protected].